I've come up with the below idea to remember things easily.

Depth-first Search
Depth-first searches are often used in simulations of games (and game-like situations in the real world). In a typical game you can choose one of several possible actions. Each choice leads to further choices, each of which leads to further choices, and so on into an ever-expanding tree-shaped graph of possibilities.

For example in games like Chess, tic-tac-toe when you are deciding what move to make, you can mentally imagine a move, then your opponent’s possible responses, then your responses, and so on. You can decide what to do by seeing which move leads to the best outcome.

Only some paths in a game tree lead to your win. Some lead to a win by your opponent, when you reach such an ending, you must back up, or backtrack, to a previous node and try a different path. In this way you explore the tree until you find a path with a successful conclusion. Then you make the first move along this path.
DFS Algorithm
1. Assign all nodes as not explored.
2. Push root node into the stack
3. When Stack is not empty, pop the first element from the stack. (While)
a) If the node is not explored, make it as explored. (If condition)
a.1) Find all edges/neighbours of this node which are not explored (For loop)
a.2) Push it into the stack.
An example of DFS
Here’s an example of what a DFS would look like. I think post order traversal in binary tree will start work from the Leaf level first. The numbers represent the order in which the nodes are accessed in a DFS:

Differences between DFS and BFS
Comparing BFS and DFS, the big advantage of DFS is that it has much lower memory requirements than BFS, because it’s not necessary to store all of the child pointers at each level. Depending on the data and what you are looking for, either DFS or BFS could be advantageous.
For example, given a family tree if one were looking for someone on the tree who’s still alive, then it would be safe to assume that person would be on the bottom of the tree. This means that a BFS would take a very long time to reach that last level. A DFS, however, would find the goal faster. But, if one were looking for a family member who died a very long time ago, then that person would be closer to the top of the tree. Then, a BFS would usually be faster than a DFS. So, the advantages of either vary depending on the data and what you’re looking for.
One more example is Facebook; Suggestion on Friends of Friends. We need immediate friends for suggestion where we can use BFS. May be finding the shortest path or detecting the cycle (using recursion) we can use DFS.
Breadth-first search
The breadth-first search has an interesting property: It first finds all the vertices that are one edge away from the starting point, then all the vertices that are two edges away, and so on. This is useful if you’re trying to find the shortest path from the starting vertex to a given vertex. You start a BFS, and when you find the specified vertex, you know the path you’ve traced so far is the shortest path to the node. If there were a shorter path, the BFS would have found it already.








Breadth-first search can be used for finding the neighbour nodes in peer to peer networks like BitTorrent, GPS systems to find nearby locations, social networking sites to find people in the specified distance and things like that.
Nice Explanation from http://www.programmerinterview.com/index.php/data-structures/dfs-vs-bfs/
BFS Algorithm
1. Assign root node as discovered and all edges as not discovered.
2. Enqueue root node
3. When Queue is not empty, dequeue the first element from the queue. (While)
a) Find all edges/neighbours of this node (For loop)
a.1) If the edge is not discovered, make it as discovered. (If condition)
a.2) Enqueue the vertex
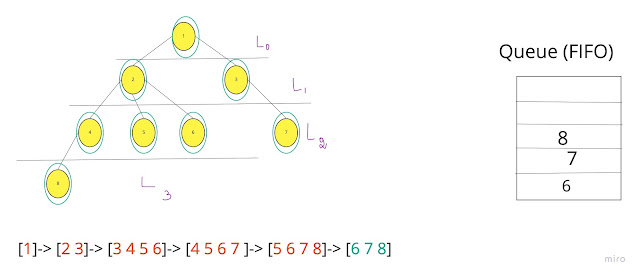
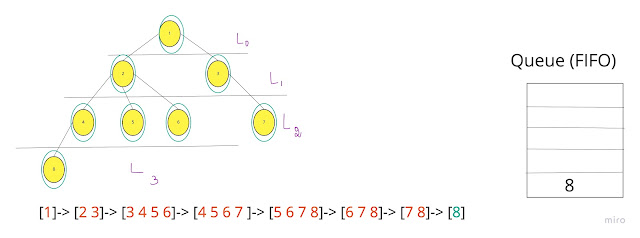
An example of BFS
Here’s an example of what a BFS would look like. This is something like Level Order Tree Traversal where we will use QUEUE with ITERATIVE approach (Mostly RECURSION will end up with DFS). The numbers represent the order in which the nodes are accessed in a BFS:

In a depth first search, you start at the root, and follow one of the branches of the tree as far as possible until either the node you are looking for is found or you hit a leaf node ( a node with no children). If you hit a leaf node, then you continue the search at the nearest ancestor with unexplored children.
The problems which can be solved using BFS are:
1. Listing all the neighbours of the node
2. Shortest Path
This is level-order traversal in tree and BFS in graph.
Breadth First Search is generally the best approach when the depth of the tree can vary, and you only need to search part of the tree for a solution. For example, finding the shortest path from a starting value to a final value is a good place to use BFS.
Depth First Search is commonly used when you need to search the entire tree. It's easier to implement (using recursion) than BFS, and requires less state: While BFS requires you store the entire 'frontier', DFS only requires you store the list of parent nodes of the current element.
References:
https://stackoverflow.com/questions/3332947/when-is-it-practical-to-use-depth-first-search-dfs-vs-breadth-first-search-bf
Comments
Post a Comment